Using Play framework database evolutions with Slick 1.0.1

This tutorial for using [Slick](http://slick.typesafe.com) with a \ [Play Framework](http://www.playframework.com) application shows you how to create your database and apply data model.
A Play framework web application that uses a relational database will generally assume that the database already exists at runtime. The database, with its tables and other objects, is an application dependency that we expect to be set-up as part of application installation. You automate this by providing SQL scripts that Play Evolutions uses to create the database.
Using the Scala console with Play and Slick shows you how to use Slick to generate the SQL DDL statements that create tables in your database, which you can use to write your SQL database creation scripts. Most of the rest is more about using Play evolutions than about Slick, but using Slick in the right way reduces the amount of work you have to do yourself.
Summary
You’ll need to know how to complete the following tasks.
-
Creating an initial Evolutions script
-
Adding test data
-
Using different databases for development and production
-
Applying data model changes
-
Automatically generating create/drop scripts
Source code: https://github.com/lunatech-labs/play-slick-examples.
Creating an initial Evolutions script
In Getting started with Play and Slick we started with a simple database table mapping:
package models.database
import play.api.db.slick.Config.driver.simple._
class Cocktails extends Table[(Long, String)]("COCKTAIL") {
def id = column[Long]("ID")
def name = column[String]("NAME")
def * = id ~ name
}To use this at runtime, you need a COCKTAIL table with ID and NAME
columns. Normally, when using evolutions, you write an SQL data
definition language (DDL) script yourself, to create the initial
database contents.
With default settings, the first evolutions script is the file
conf/evolutions/default/1.sql. When evolutions are enabled, Play will
run this script when the application starts, if it hasn’t run it before.
Instead of writing it by hand, use
play-slick to generate it:
-
follow the getting started instructions to set-up your application
-
add the table mapping in
app/models/database/Cocktails.scala -
tell Slick where the table mappings are with the following addition to the Play configuration in
conf/application.conf:
slick.default="models.database.*"Now run the application (in DEV mode) - Slick creates the initial script
in conf/evolutions/default/1.sql:
# --- Created by Slick DDL
# To stop Slick DDL generation, remove this comment and start using Evolutions
# --- !Ups
create table "COCKTAIL" ("ID" BIGINT NOT NULL,"NAME" VARCHAR NOT NULL);
# --- !Downs
drop table "COCKTAIL";After Slick creates this Script, Play will see that there is a new Evolutions script and offer to run it:
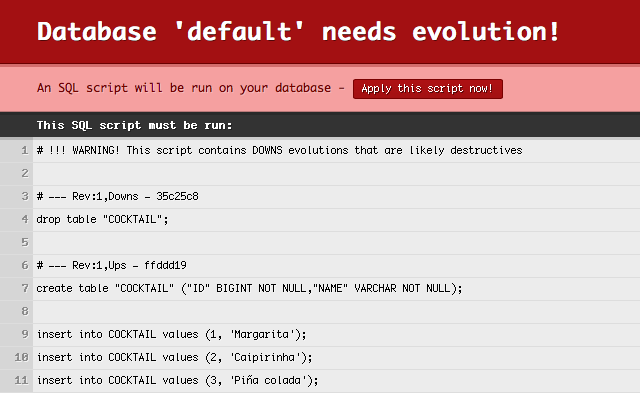
Now you have a database for your application to use at runtime.
Adding test data
The initial SQL script that Slick generates will create a database with empty tables. In practice, your application will be more interesting if it has some data, but the first release of an application probably doesn’t have functionality to edit data in place yet. Especially if you deploy to the test server after every feature so that your customer can see continuous delivery. It can be useful to add test data at this stage, to avoid blank pages.
To add initial data to your application, add it to your evolutions script. Start with three classic cocktails:
insert into COCKTAIL values (1, 'Margarita');
insert into COCKTAIL values (2, 'Caipirinha');
insert into COCKTAIL values (3, 'Piña colada');In DEV mode, Play will detect the change on the next request and offer to run the new script.
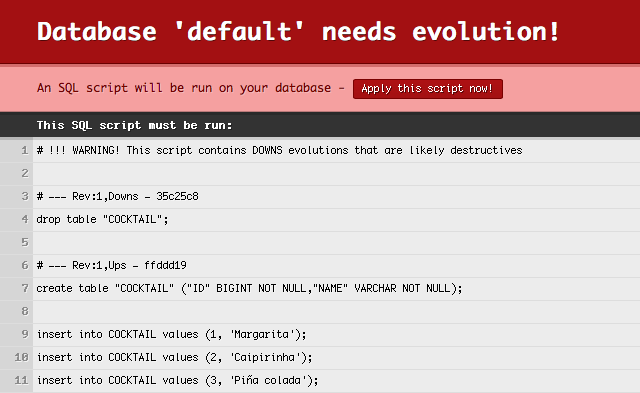
As you can see, Play will first run a Downs section that drops the
table. This is the Downs section from the previous version of the
script, which Play stored in the database. This safely reverts the
database to its state before Play ran the first version of 1.sql,
before applying the Ups from the second version of the same script. As
you work on adding test data to 1.sql you will repeat this process for
each change: modify the script, reload the page in the browser, and
apply evolutions to reapply the script.
This is is what you want during development, but once you have deployed
a production release, it is important not to change 1.sql again. If
you do, Play will have to run the Downs from all of the scripts
applied so far, which is generally destructive, before applying all of
the Ups in the correct order. Instead, only make changes in evolution
scripts that have not been run on production yet. You can check this by
querying the play_evolutions table.
SQL insert statements are fine for small amounts of tests data. If
you’re going to import a truly huge amount of data, then you might want
something else that will be less verbose and will perform better. For
example, PostgreSQL’s COPY command lets you insert tab-separated data
that you provide in-line or in a separate file.
Using different databases for development and production
You may want to use different databases for development and test/production, so you can use an in-memory H2 database for development and MySQL production, for example.
This works, because play-slick uses the Slick driver for the database specified by the current Play configuration. This means that you can use a different Play configuration for the production database and queries will continue to work at runtime, because Slick generates SQL in the correct database-specific dialect.
However, you still have hand-written SQL in your evolutions SQL scripts,
which will then have to work on both development and production
databases. This is possible, if you stick to standard SQL that both
databases support, but this is likely to be too limiting for
create table DDL statements, where you generally use database-specific
column types.
If you do try writing cross-database SQL scripts, you probably won’t be able to quote table names, because the quoting characters vary:
create table "COCKTAILS" -- H2 uses double quotes create table `COCKTAILS` -- MySQL uses backticks
In SQL, quoted table names are case-sensitive while unquoted names are
not, which is reasonable. What you might not expect is that if you’re
using H2 create table cocktails creates a table called COCKTAILS,
not cocktails, which makes your queries fail at runtime if you use
lower-case names in your Slick table definition:
[JdbcSQLException: Table "cocktail" not found; SQL statement:
select x2."id", x2."name" from "cocktail" x2 [42102-168]]An alternative might be to have separate evolutions SQL scripts, but there isn’t an obvious way to do this and it’s duplication that you probably don’t want anyway. Ideally, in the case of H2, you would just use it’s MySQL compatibility mode in development, and use MySQL dialect in your SQL scripts. However, this won’t work because Slick will still generate H2 dialect SQL for queries at runtime.
For now, our conclusion is that you have to use the same database in
production and development. Fortunately - if you’re using MySQL on OSX,
say - this isn’t much harder than brew install mysql.
Applying data model changes
The first production release is straightforward: you have a single evolutions file, generated by Slick, possibly with additional test data. What’s harder is when your next production release includes data model changes. You need to know how to write a second evolutions SQL script that modifies the existing database to change it to the new data model, without destroying existing data.
The good news is that most database platforms make it easy to modify existing tables using SQL DDL, so you can refactor your data model by changing table definitions. If you have a DBA who tells you that the data model is written in stone and must not be changed, then you’re more likely to need a new DBA than a new database platform.
Changing the table definitions is actually the easy part: preserving the
data is the tricky part. Some tricks are standard: when you add a
NOT NULL column, you either specify a default value or you add the
column without the constraint, set the value for all existing rows and
then add the constraint. Some issues are less obvious.
Suppose you have a database table with non-empty date columns for recording when the record was created and updated. A good default value for both fields is the current date and time. However, MySQL currently only allows one date column to have a default value. This means that you have to add an additional update statement to fix the other column’s value.
alter table COCKTAILS add column CREATED TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP;
alter table COCKTAILS add column UPDATED TIMESTAMP;
update COCKTAILS set UPDATED = CREATED where UPDATED = '0000-00-00 00:00:00';In general, you need to do something similar for every data model
change: whenever you add or change a column, think about what the new
values for that column should be. Note that this still applies if your
data model change is to remove a column, because the Downs section in
the script has to revert the change by adding the column again and
somehow repopulating its contents.
Automatically generating create/drop scripts
To write the SQL scripts for applying data model changes, you need to know the correct syntax for things like column types and indexes. It’s convenient to use Slick to generate a complete `create database' script for the current database, so that you can use its differences to the previous version to identify which changes are needed, and what the new syntax is.
It is also convenient to have `create database' and `drop database' scripts if you want to create a complete database without using Play evolutions. Running both scripts is a quick way to reset the whole database to empty tables.
As you saw earlier, Slick only generates the initial SQL: script if you
haven’t already already created one. Instead, you can write your own
code to generate create-database.sql and drop-database.sql scripts
when the application starts in development mode. The following class is
a Play GlobalSettings that does just that, based on the code from the
play-slick’s play.api.db.slick.SlickDDLPlugin Play plug-in.
import java.io.File
import play.api.db.slick.plugin.TableScanner
import play.api.libs.Files
import play.api.{Mode, Application, GlobalSettings}
object Global extends GlobalSettings {
private val configKey = "slick"
private val ScriptDirectory = "conf/evolutions/"
private val CreateScript = "create-database.sql"
private val DropScript = "drop-database.sql"
private val ScriptHeader = "-- SQL DDL script\n-- Generated file - do not edit\n\n"
/**
* Creates SQL DDL scripts on application start-up.
*/
override def onStart(application: Application) {
if (application.mode != Mode.Prod) {
application.configuration.getConfig(configKey).foreach { configuration =>
configuration.keys.foreach { database =>
val databaseConfiguration = configuration.getString(database).getOrElse{
throw configuration.reportError(database, "No config: key " + database, None)
}
val packageNames = databaseConfiguration.split(",").toSet
val classloader = application.classloader
val ddls = TableScanner.reflectAllDDLMethods(packageNames, classloader)
val scriptDirectory = application.getFile(ScriptDirectory + database)
Files.createDirectory(scriptDirectory)
writeScript(ddls.map(_.createStatements), scriptDirectory, CreateScript)
writeScript(ddls.map(_.dropStatements), scriptDirectory, DropScript)
}
}
}
}
/**
* Writes the given DDL statements to a file.
*/
private def writeScript(ddlStatements: Seq[Iterator[String]], directory: File,
fileName: String): Unit = {
val createScript = new File(directory, fileName)
val createSql = ddlStatements.flatten.mkString("\n\n")
Files.writeFileIfChanged(createScript, ScriptHeader + createSql)
}
}This will create or update both scripts in the conf/evolutions/default
directory (if changed). Add these files to version control, even though
they are generated, so that you get SQL diffs when you make changes.
Next steps
Now you have created an initial database and populated it with test data, you can:
-
insert, update and delete data.