Parcourir des collections avec foldLeft et foldRight
Il y a quelques temps, j’ai été chargé de développer un petit algorithme pour mon projet. Il s’agissait de parcourir toutes les images d’une séquence vidéo afin de déterminer quel label apposé manuellement occupait le plus d’images au sein de cette séquence. Cet exercice m’a permis de (re)découvrir une fonction que je n’utilise que trop rarement au quotidien, le foldLeft (et son corollaire, le foldRight).
Ces méthodes, qui permettent de parcourir des listes effectuant des opérations entre la valeur courante et la valeur précédente tout en permettant de retourner un type complètement différent, méritent qu’on s’y attarde un peu.
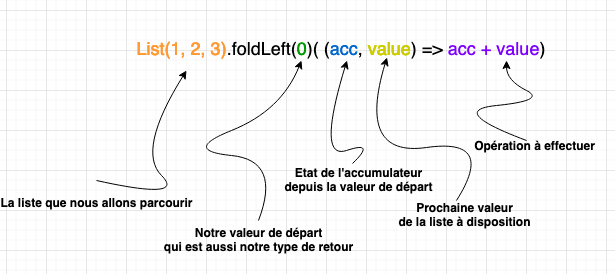
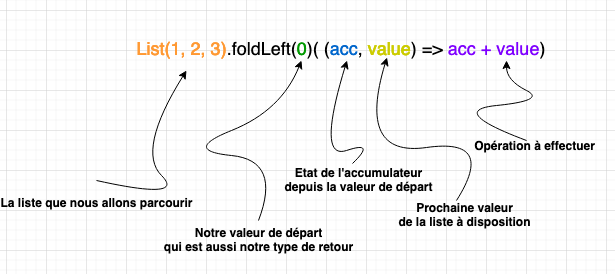
Intéressons-nous tout d’abord à la signature de cette méthode :
def foldLeft[B](z: B)(op: (B, A) => B): BNous voyons ici plusieurs choses intéressantes :
-
La fonction retourne une instance de type B, qui est le type de sortie
-
foldLeft a deux listes de paramètres. Le premier est un seul paramètre
zdu type B mentionné ci-dessus. Ce paramètre est important car il est le point de départ de l’itération, et il est utilisé pour l’initialiser et pour collecter les résultats. Nous nous y référerons comme à l’accumulateur -
Et en second paramètre "op" (opération) une fonction qui prend deux paramètres (B, le type de sortie et A , le type des éléments de la liste) et qui permet d’obtenir ce fameux type de sortie B.
Pour résumer, cette fonction va parcourir tous les éléments de la liste [A] et va collecter le résultat dans l’accumulateur [B]. A la fin, on se retrouve avec [B].
Commençons par un exemple simple. Nous allons additionner chaque chiffre d’une liste avec son prédécesseur pour obtenir la somme de cette liste.
val numbers = List(1, 2, 3, 4)
numbers.foldLeft[Int](z = 0)(op = (accumulator, number) => accumulator + number)
// Ecriture simplifiée
numbers.foldLeft(0)(_ + _)
// Result => Out: Int = 10En réalité, nous pouvons utiliser ici la méthode reduce qui n’utilise pas de condition initiale et retourne le même type qu’en entrée.
val numbers = List(1, 2, 3, 4)
numbers.reduce(_ + _)
// Ce qui equivaut à
numbers.sum
// Result => Out: Int = 10Rapprochons-nous petit à petit de cas plus concrets.
Dans l’exemple suivant, je voudrais, non pas faire la somme des chiffres de la liste, mais obtenir une nouvelle liste dont chaque chiffre serait l’addition du chiffre de la liste "numbers" avec son prédécesseur.
Nous allons parcourir la liste "List(1, 2, 3, 4)" et à chaque itération, faire cette opération :
-
accumulateur vide et chiffre courant = 1. Résultat : accumulateur = List(1)
-
accumulateur (1) et chiffre courant = 2. Résultat : accumulateur = List(1, 2+1)
-
accumulateur (1, 3) et chiffre courant = 3. Résultat : accumulateur = List(1, 3, 3+3)
-
accumulateur (1, 3, 6) et chiffre courant = 4. Résultat : accumulateur = List(1, 3, 6, 4+6)
Résultat final : newList = List(1, 3, 6, 10)
Une écriture possible peut s’appuyer sur un pattern matching avec une condition dédiée à la première itération. Comme nous n’avons rien à additionner au début, nous remplissons simplement la liste avec le premier chiffre. Si nous ne considérons pas ce cas, nous démarrons avec une liste vide qui donnera une erreur à l’exécution car nous feront accumulator.last sur une liste vide.
Cette implémentation comporte quelques problèmes de performances que nous aborderons à la fin de l’article.
val numbers = List(1, 2, 3, 4)
val newList: Seq[Int] = numbers.foldLeft[Seq[Int]](Seq.empty) {
case (accumulator, number) if accumulator.isEmpty => accumulator :+ number
case (accumulator, number) => accumulator :+ (accumulator.last + number)
}
println(newList)
// Result => List(1, 3, 6, 10)Travailler avec des types d’entrée et de sortie différents
Allons un peu plus loin. Imaginons que notre type de sortie soit différent de notre type d’entrée, par exemple pour ajouter des données calculées à une entité destinée à être persistée en base de données à partir d’un objet venant d’une API.
Dans le cas présent, l’utilisateur renseignerait un nom et une date de naissance dans une interface graphique et le système calcule l’âge et la différence d’âge avec son prédécesseur avant de le sauvegarder.
Le calcul de l’intervalle n’a pas vraiment d’intérêt, mais ça va nous permettre de faire quelques calculs et d’observer que foldLeft et foldRight ne donnent pas systématiquement les mêmes résultats même si nous leur donnons les mêmes données en entrée (la condition pour que ces deux méthodes retournent le même résultat vient du fait que la fonction op doit être à la fois commutative et associative).
Une écriture possible pourrait être la suivante :
import java.time.LocalDate
case class UserApi(name: String, birthYear: Int)
case class UserData(name: String, birthYear: Int, age: Int, deltaWithPrecedent: Int)
val user1 = UserApi("Marc", 1982)
val user2 = UserApi("Pierre", 1995)
val user3 = UserApi("Marie", 1987)
val user4 = UserApi("Lydia", 1987)
val user5 = UserApi("Sophie", 1990)
val userList = Seq(user1, user2, user3, user4, user5)
private def computeAge(birthYear: Int) = LocalDate.now.getYear - birthYear
private def computeDeltaWithPrecedent(birthYear: Int, precedentBirthYear: Int) = birthYear - precedentBirthYear
def computeUserDatas(users: Seq[UserApi]): Seq[UserData] =
users
.sortBy(user => (user.birthYear, user.name)) // On trie d'abord par "birthYear", puis par "name"
.foldLeft[Seq[UserData]](Seq.empty) { (acc, user) =>
val userDataList = if (acc.isEmpty) {
acc :+ UserData(
user.name,
user.birthYear,
computeAge(user.birthYear),
0
)
}
else acc :+ UserData(
user.name,
user.birthYear,
computeAge(user.birthYear),
computeDeltaWithPrecedent(user.birthYear, acc.last.birthYear)
)
userDataList
}
computeUserDatas(userList).foreach(println)
/* Result => Chaque intervalle est calculé par rapport à l'année inférieure
UserData(Marc,1982,40,0)
UserData(Lydia,1987,35,5)
UserData(Marie,1987,35,0)
UserData(Sophie,1990,32,3)
UserData(Pierre,1995,27,5)
*/Inverser le parcours avec foldRight
Si nous utilisons maintenant un foldRight sur notre liste de UserApi, nous pouvons parcourir la liste depuis la fin vers le début.
Dans ce cas, le calcul de l’intervalle s’opère non pas entre la valeur courante et sa précédente à gauche, mais entre la valeur courante et sa précédente à droite. Le résultat de l’intervalle entre les dates de naissance sera donc différent.
Dans l’exemple suivant, j’utilise un écriture un peu plus concise et j’ai réorganisé le code en intégrant les deux méthodes privées à l’intérieur de la méthode principale.
import java.time.LocalDate
case class UserApi(name: String, birthYear: Int)
case class UserData(name: String, birthYear: Int, age: Int, deltaWithPrecedent: Int)
val user1 = UserApi("Marc", 1982)
val user2 = UserApi("Pierre", 1995)
val user3 = UserApi("Marie", 1987)
val user4 = UserApi("Lydia", 1987)
val user5 = UserApi("Sophie", 1990)
val userList = Seq(user1, user2, user3, user4, user5)
def computeUserDatas(users: Seq[UserApi]): Seq[UserData] =
users
.sortBy(user => (user.birthYear, user.name))
// La paire (valeur courante, accumulateur) est inversée par rapport au foldLeft
.foldRight[Seq[UserData]](Seq.empty) { (user, acc) =>
def computeAge(birthYear: Int) = LocalDate.now.getYear - birthYear
// Il faut inverser le sens de l'opération pour éviter les résultats négatifs, ou utiliser (birthYear - precedentBirthYear).abs
def computeDeltaWithPrecedent(birthYear: Int, precedentBirthYear: Int) = precedentBirthYear - birthYear
if (acc.isEmpty)
acc :+ UserData(
user.name,
user.birthYear,
computeAge(user.birthYear),
0
) else acc :+ UserData(
user.name,
user.birthYear,
computeAge(user.birthYear),
computeDeltaWithPrecedent(user.birthYear, acc.last.birthYear)
)
}
computeUserDatas(userList).foreach(println)
/* Result => (chaque intervalle est calculé par rapport à l'année supérieure)
UserData(Pierre,1995,27,0)
UserData(Sophie,1990,32,5)
UserData(Marie,1987,35,3)
UserData(Lydia,1987,35,0)
UserData(Marc,1982,40,5)
*/Gérer une exception avec Either et Cats
Pour finir, voici un exemple un peu plus complexe pour gérer les exceptions, d’abord avec un Either, ensuite avec la librairie Cats.
Imaginons que nous gérions une équipe (Team) constituée de joueurs (Player) qui peuvent prendre différents statuts au fil du temps. Imaginons encore que nous disposions d’un endpoint permettant de supprimer les joueurs en leur attribuant le statut Deleted sauf si un joueur dispose du statuts Enrolled (inscrit à une compétition par exemple, auquel cas, sa suppression poserait quelques problèmes).
Pour une raison quelconque (en fait, pour la très bonne raison que ça sert mon exemple), on sauvegarde toute la liste ou rien du tout. L’idée ici est donc d’interrompre le traitement et de renvoyer une exception dans un Left si un Player au statuts Enrolled est trouvé dans la liste, ce qui est le cas ici.
import scala.concurrent.{ Await, ExecutionContextExecutor, Future }
import scala.concurrent.duration.DurationInt
implicit val executor: ExecutionContextExecutor = scala.concurrent.ExecutionContext.global
sealed trait PlayerStatus
object PlayerStatus {
case object Available extends PlayerStatus
case object Enrolled extends PlayerStatus
case object Resting extends PlayerStatus
case object Deleted extends PlayerStatus
}
case class Player(name: String, currentStatus: PlayerStatus) {
def updateStatus(
status: PlayerStatus
): Either[Exception, Player] =
if (currentStatus == PlayerStatus.Enrolled) Left(new IllegalArgumentException(s"status is $currentStatus"))
else Right(copy(currentStatus = status))
}
case class Team(players: Seq[Player])
val team = Team(
Seq(
Player("player1", PlayerStatus.Available),
Player("player2", PlayerStatus.Resting),
Player("player3", PlayerStatus.Enrolled) // Le statut qui provoque l'interruption
)
)
val resultEither: Future[Either[IllegalArgumentException, Seq[Player]]] =
for {
updatedPlayers <- Future.successful {
team.players
.map(_.updateStatus(PlayerStatus.Deleted))
.foldLeft[Either[Exception, Seq[Player]]](Right(Seq.empty[Player])) { (acc, current) =>
acc.flatMap { players =>
current.map(_ +: players)
}
}
.left
.map(error => new IllegalArgumentException(s"Unable to delete the player due to ${error.getMessage}"))
}
} yield updatedPlayers
Await.result(resultEither, 1.second)
/* Result =>
Left(java.lang.IllegalArgumentException: Unable to delete the task due to status is Enrolled)
*/Quelques précisions :
acc.flatMap { players =>
current.map(_ +: players)
}Le flatMap permet d’accéder à la Séquence de Player située dans le Right du Either de l’accumulateur et de renvoyer un Either[Exception, Seq[Player]] au lieu d’un Either[Exception, Either[Exception, Seq[Player]]].
.left
.map(error => ...S’il n’y a pas de Right, alors le Left est considéré comme un type de retour. Comme il n’y a qu’un seul Left possible dans notre type de retour Either[Exception, Seq[Player]], alors le traitement est interrompu dès qu’il est renseigné.
Avec la librairie Cats, nous pouvons écrire le code de la manière suivante :
import cats.data.{EitherT, Validated}
import cats.implicits._
import scala.concurrent.duration.DurationInt
import scala.concurrent.{Await, ExecutionContextExecutor, Future}
implicit val executor: ExecutionContextExecutor = scala.concurrent.ExecutionContext.global
sealed trait PlayerStatus
object PlayerStatus {
case object Available extends PlayerStatus
case object Enrolled extends PlayerStatus
case object Resting extends PlayerStatus
case object Deleted extends PlayerStatus
}
case class Player(name: String, currentStatus: PlayerStatus) {
def updateStatus(
status: PlayerStatus
): Validated[Exception, Player] =
if (currentStatus == PlayerStatus.Enrolled)
Validated.invalid[Exception, Player](new IllegalArgumentException(s"status is $currentStatus"))
else Validated.valid[Exception, Player](copy(currentStatus = status))
}
case class Team(players: Seq[Player])
val team = Team(
Seq(
Player("player1", PlayerStatus.Available),
Player("player2", PlayerStatus.Resting),
Player("player3", PlayerStatus.Enrolled) // Le statut qui provoque l'interruption
)
)
val resultEitherT: EitherT[Future, IllegalArgumentException, Seq[Player]] =
for {
updatedPlayers <- EitherT.fromEither[Future] {
team.players
.map(_.updateStatus(PlayerStatus.Deleted))
.foldLeft[Validated[Exception, Seq[Player]]](Validated.Valid(Seq.empty[Player])) { (acc, current) =>
acc.andThen { players =>
current.map(_ +: players)
}
}
.leftMap(error => new IllegalArgumentException(s"Unable to delete the task due to ${error.getMessage}"))
.toEither
}
} yield updatedPlayers
Await.result(resultEitherT.value, 1.second)
/* Result =>
Left(java.lang.IllegalArgumentException: Unable to delete the task due to status is Enrolled)
*/Peut-être avez-vous remarqués cette portion de code :
acc.andThen { players =>
current.map(_ +: players)
}Là encore, il s’agit de la version Cats de left.map(…)
Enfin, nous enveloppons notre bloc de EitherT.fromEither[Future] { { … }.toEither } pour passer du type Validated au type EitherT. Notez que que EitherT and Validated sont deux types spécifiques à Cats.
Performances
Si vous vous souvenez, j’ai proposé cette implémentation au début de l’article :
val numbers = List(1, 2, 3, 4)
val newList: Seq[Int] = numbers.foldLeft[Seq[Int]](Seq.empty) {
case (accumulator, number) if accumulator.isEmpty => accumulator :+ number
case (accumulator, number) => accumulator :+ (accumulator.last + number)
}
println(newList)
// Result => List(1, 3, 6, 10)En réalité, on a initialisé l’accumulateur avec Seq.empty[Int] alors que la liste proposée est de type List. Comme le type est générique (foldLeft prend une Seq[Int]), le compilateur va attribuer le type List de notre liste de nombres à l’accumulateur. Le problème pour les performances vient du fait que le type List va se retrouver à chaque étape du traitement des éléments de la liste :
-
lors de la récupération du dernière élément de la liste (
accumulator.last) -
lors de l’ajout du nouvel élément à la fin de la list (
accumulator :+ …)
Pour le accumulator.last, l’implémentation dans Scala supprime le premier élément, puis regarde combien il y a d’éléments restant dans la liste. Il va recommencer de cette manière jusqu’à ce qu’il ne reste plus qu’un seul élément à retourner.
Si on se réfère à la documentation scala sur les performances des collections, l’opération d’ajout d’éléments à une collection de type List prend d’autant plus de temps que la liste est grande.
Pour régler ce problème tout en restant générique, on peut réecrire notre méthode de cette façon :
List(1,2,3,4).foldLeft(Seq.empty[Int]) {
case (Nil, element) => Seq(element)
case (accumulator, element) => (accumulator.head + element) +: accumulator
}.reverseDe cette manière, accéder ou ajouter un élément à l’accumulateur se fera selon une opération à temps constant (rapide). Mais comme cette implémentation produit un résultat inversé, il suffit d’ajouter un .reverse à la fin, ou d’utiliser un foldRight, dont on remarquera qu’il s’agit juste d’un foldLeft inversé.
def foldRight[B](z: B)(op: (A, B) ⇒ B): B = reversed.foldLeft(z)b, a) ⇒ op(a, b
Conclusion
Comme nous l’avons vu dans cet article, foldLeft et foldRight sont des méthodes très puissantes qui peuvent être considérées comme l’équivalent du couteau suisse de la bibliothèque de collections de Scala : elles opèrent sur une collection d’éléments d’un certain type A et peuvent générer une valeur qui est du même type A ou d’un type B complètement différent.
J’espère que cet article vous aura éclairé sur la manière de les utiliser simplement et vous aura convaincu d’en user et même d’en abuser !
Merci à Vincent et Eric pour leur contribution et relecture attentive.